
헬로티 함수미 기자 |
를 통해 전 세계 아마존 프라임(Amazon Prime) 사이트 사용자들에게 나타난 문제 확인 (출처 : 시스코)")
시스코는 자사의 네트워크 분석 솔루션인 사우전드아이즈를 통해 최근 미국에서 발생한 아마존웹서비스(이하 AWS)의 서비스 장애 분석 결과를 공개했다.
시스코는 이번 결과를 통해 초연결 시대에서 보다 안전한 클라우드 서비스 운영 관리를 위해서는 완전한 가시성 확보와 사고 예방을 위한 사전 준비가 중요하다고 강조했다.

미국 현지시간 2021년 12월 7일 AWS 서비스에서 발생한 갑작스러운 장애로 인해 아마존 클라우드를 기반으로 하는 스마트 가전제품에서부터 기업 고객에 제공되는 서비스가 약 8시간 이상 운영 중단되는 사태가 발생했다.
또한 12월 10일 금요일에는 약 1시간가량의 ‘애프터 쇼크’ 서비스 장애가 추가로 나타났다. 사우전드아이즈는 이번 사태가 클라우드 이용량 급증에 따른 디지털 생태계의 취약점과 복잡성을 보여준다고 설명했다.
사우전드아이즈는 AWS를 포함한 주요 글로벌 클라우드 사업자 및 SaaS 어플리케이션을 상시 모니터링하고 있으며, 이번 AWS 사태를 면밀히 분석했다.
지난 12월 7일 오전 7시 35분 첫 접속 장애가 발생하며 여러 아마존 사이트와 서비스의 성능이 상당 수준 저하된 것으로 확인했다. 이후 오전 8시 50분 대다수 사이트 로딩이 정상화되는 듯 보였으나, 이후 AWS의 API 트랜잭션 시간이 크게 증가하거나 시간 초과되는 서비스 오류를 발견했다.
AWS는 다양한 클라우드 서비스를 제공하는데, 이들 서비스의 아키텍처를 살펴보면 여러 계층이 서로 의존적으로 설계되어 일부 서비스에서 나타난 오류는 다른 서비스에도 영향을 줄 수 있다.
이는 광범위한 연쇄 장애를 초래할 수도 있다. 특히 클라우드, SaaS 수요가 지속 증가하고 이 같은 서비스 업체에 대한 의존도가 높아짐에 따라 운영 복잡성은 더욱 높아지고 있다.
이번 AWS 사태처럼 예측할 수 없는 문제에 미리 대비하기 위해서는 애플리케이션 아키텍처 취약점에 대한 이해도를 높이고, 조치 필요 시점을 조기 파악하는 등 사전 준비가 필요하다.
사우전드아이즈는 운영 상황을 살펴볼 수 있는 가시성과 인사이트를 기반으로 AWS 사고 범위를 실시간으로 확인하고, 문제의 원인과 해당 문제가 어떤 서비스에 영향을 미쳤는지 신속히 파악할 수 있었다.
이처럼 기업 IT 서비스를 담당하는 팀은 문제 해결을 위해 어떤 조치를 취해야 하는지 미리 숙지해야 한다. 또한 문제가 모두 해결됐을 시 이에 대한 검증이 이뤄져야 한다. 즉, 내부 또는 외부 요소에 의한 문제인지 즉각적으로 파악해야 한다.
시스코는 이를 위해 네트워크 모든 계층에서 엔드-투-엔드 가시성을 확보하고 서비스 운영에 필요한 인사이트 활용이 중요하다고 강조했다.






































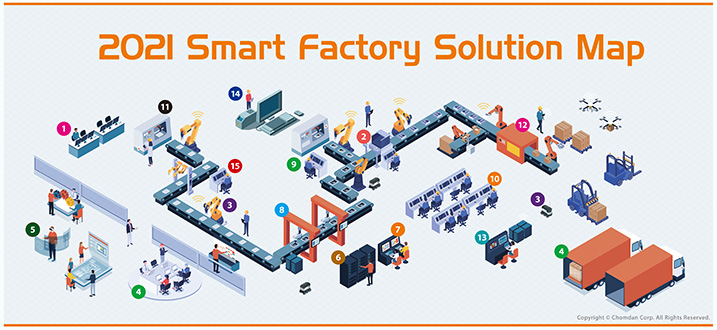





























/pdf.png)
/smartmap_2_01.png)
/smartmap_2_04.png)
/smartmap_2_big_04.jpg)
/smartmap_2_05.png)
/smartmap_2_big_05.jpg)
/smartmap_2_08.png)
/smartmap_2_big_09.jpg)
/smartmap_2_09_2.png)
/smartmap_2_big_10_2.jpg)

/smartmap_2_11_2.png)
/smartmap_2_big_12_2.jpg)
/smartmap_2_02.png)
/smartmap_2_03.png)
/smartmap_2_06.png)
/smartmap_2_big_07.jpg)
/smartmap_2_07.png)
/smartmap_2_big_08.jpg)
/smartmap_2_12.png)
/smartmap_2_big_13.jpg)
/smartmap_2_13.png)
/smartmap_2_big_14.jpg)
/smartmap_2_14.png)
/smartmap_2_big_15.jpg)
/smartmap_2_15.png)
/smartmap_2_big_16.jpg)
/smartmap_2_16.png)
/smartmap_2_big_17.jpg)
/smartmap_2_17_2.png)
/smartmap_2_big_18_2.jpg)
/smartmap_2_18_2.png)
/smartmap_2_big_19_2.jpg)
/smartmap_2_19._2.png)
/smartmap_2_big_20_2.jpg)
/smartmap_2_20.png)
/smartmap_2_big_21.jpg)
/smartmap_2_21.png)
/smartmap_2_22.png)
/smartmap_2_23.png)
/smartmap_2_24.png)
/smartmap_2_25.png)
/smartmap_2_26.png)
/smartmap_2_27.jpg)